💥 OpenAI Proxy Server
LiteLLM Server manages:
- Calling 100+ LLMs Huggingface/Bedrock/TogetherAI/etc. in the OpenAI
ChatCompletions&Completionsformat - Load balancing - between Multiple Models + Deployments of the same model LiteLLM proxy can handle 1k+ requests/second during load tests
- Authentication & Spend Tracking Virtual Keys
Quick Start
View all the supported args for the Proxy CLI here
$ pip install litellm
$ litellm --model huggingface/bigcode/starcoder
#INFO: Proxy running on http://0.0.0.0:8000
Test
In a new shell, run, this will make an openai.chat.completions request. Ensure you're using openai v1.0.0+
litellm --test
This will now automatically route any requests for gpt-3.5-turbo to bigcode starcoder, hosted on huggingface inference endpoints.
Using LiteLLM Proxy - Curl Request, OpenAI Package
- Curl Request
- OpenAI v1.0.0+
curl --location 'http://0.0.0.0:8000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:8000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(model="gpt-3.5-turbo", messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
])
print(response)
Server Endpoints
- POST
/chat/completions- chat completions endpoint to call 100+ LLMs - POST
/completions- completions endpoint - POST
/embeddings- embedding endpoint for Azure, OpenAI, Huggingface endpoints - GET
/models- available models on server - POST
/key/generate- generate a key to access the proxy
Supported LLMs
All LiteLLM supported LLMs are supported on the Proxy. Seel all supported llms
- AWS Bedrock
- Azure OpenAI
- OpenAI
- Huggingface (TGI) Deployed
- Huggingface (TGI) Local
- AWS Sagemaker
- Anthropic
- VLLM
- TogetherAI
- Replicate
- Petals
- Palm
- AI21
- Cohere
$ export AWS_ACCESS_KEY_ID=
$ export AWS_REGION_NAME=
$ export AWS_SECRET_ACCESS_KEY=
$ litellm --model bedrock/anthropic.claude-v2
$ export AZURE_API_KEY=my-api-key
$ export AZURE_API_BASE=my-api-base
$ litellm --model azure/my-deployment-name
$ export OPENAI_API_KEY=my-api-key
$ litellm --model gpt-3.5-turbo
$ export HUGGINGFACE_API_KEY=my-api-key #[OPTIONAL]
$ litellm --model huggingface/<your model name> --api_base https://k58ory32yinf1ly0.us-east-1.aws.endpoints.huggingface.cloud
$ litellm --model huggingface/<your model name> --api_base http://0.0.0.0:8001
export AWS_ACCESS_KEY_ID=
export AWS_REGION_NAME=
export AWS_SECRET_ACCESS_KEY=
$ litellm --model sagemaker/jumpstart-dft-meta-textgeneration-llama-2-7b
$ export ANTHROPIC_API_KEY=my-api-key
$ litellm --model claude-instant-1
$ litellm --model vllm/facebook/opt-125m
$ export TOGETHERAI_API_KEY=my-api-key
$ litellm --model together_ai/lmsys/vicuna-13b-v1.5-16k
$ export REPLICATE_API_KEY=my-api-key
$ litellm \
--model replicate/meta/llama-2-70b-chat:02e509c789964a7ea8736978a43525956ef40397be9033abf9fd2badfe68c9e3
$ litellm --model petals/meta-llama/Llama-2-70b-chat-hf
$ export PALM_API_KEY=my-palm-key
$ litellm --model palm/chat-bison
$ export AI21_API_KEY=my-api-key
$ litellm --model j2-light
$ export COHERE_API_KEY=my-api-key
$ litellm --model command-nightly
Using with OpenAI compatible projects
Set base_url to the LiteLLM Proxy server
- OpenAI v1.0.0+
- ContinueDev
- Aider
- AutoGen
- guidance
- LibreChat
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:8000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(model="gpt-3.5-turbo", messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
])
print(response)
Continue-Dev brings ChatGPT to VSCode. See how to install it here.
In the config.py set this as your default model.
default=OpenAI(
api_key="IGNORED",
model="fake-model-name",
context_length=2048, # customize if needed for your model
api_base="http://localhost:8000" # your proxy server url
),
Credits @vividfog for this tutorial.
$ pip install aider
$ aider --openai-api-base http://0.0.0.0:8000 --openai-api-key fake-key
pip install pyautogen
from autogen import AssistantAgent, UserProxyAgent, oai
config_list=[
{
"model": "my-fake-model",
"api_base": "http://localhost:8000", #litellm compatible endpoint
"api_type": "open_ai",
"api_key": "NULL", # just a placeholder
}
]
response = oai.Completion.create(config_list=config_list, prompt="Hi")
print(response) # works fine
llm_config={
"config_list": config_list,
}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy")
user_proxy.initiate_chat(assistant, message="Plot a chart of META and TESLA stock price change YTD.", config_list=config_list)
Credits @victordibia for this tutorial.
NOTE: Guidance sends additional params like stop_sequences which can cause some models to fail if they don't support it.
Fix: Start your proxy using the --drop_params flag
litellm --model ollama/codellama --temperature 0.3 --max_tokens 2048 --drop_params
import guidance
# set api_base to your proxy
# set api_key to anything
gpt4 = guidance.llms.OpenAI("gpt-4", api_base="http://0.0.0.0:8000", api_key="anything")
experts = guidance('''
{{#system~}}
You are a helpful and terse assistant.
{{~/system}}
{{#user~}}
I want a response to the following question:
{{query}}
Name 3 world-class experts (past or present) who would be great at answering this?
Don't answer the question yet.
{{~/user}}
{{#assistant~}}
{{gen 'expert_names' temperature=0 max_tokens=300}}
{{~/assistant}}
''', llm=gpt4)
result = experts(query='How can I be more productive?')
print(result)
Proxy Configs
The Config allows you to set the following params
| Param Name | Description |
|---|---|
model_list | List of supported models on the server, with model-specific configs |
litellm_settings | litellm Module settings, example litellm.drop_params=True, litellm.set_verbose=True, litellm.api_base, litellm.cache |
general_settings | Server settings, example setting master_key: sk-my_special_key |
environment_variables | Environment Variables example, REDIS_HOST, REDIS_PORT |
Example Config
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-eu
api_base: https://my-endpoint-europe-berri-992.openai.azure.com/
api_key:
rpm: 6 # Rate limit for this deployment: in requests per minute (rpm)
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key:
rpm: 6
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-large
api_base: https://openai-france-1234.openai.azure.com/
api_key:
rpm: 1440
litellm_settings:
drop_params: True
set_verbose: True
general_settings:
master_key: sk-1234 # [OPTIONAL] Only use this if you to require all calls to contain this key (Authorization: Bearer sk-1234)
environment_variables:
OPENAI_API_KEY: sk-123
REPLICATE_API_KEY: sk-cohere-is-okay
REDIS_HOST: redis-16337.c322.us-east-1-2.ec2.cloud.redislabs.com
REDIS_PORT: "16337"
REDIS_PASSWORD:
Config for Multiple Models - GPT-4, Claude-2
Here's how you can use multiple llms with one proxy config.yaml.
Step 1: Setup Config
model_list:
- model_name: zephyr-alpha # the 1st model is the default on the proxy
litellm_params: # params for litellm.completion() - https://docs.litellm.ai/docs/completion/input#input---request-body
model: huggingface/HuggingFaceH4/zephyr-7b-alpha
api_base: http://0.0.0.0:8001
- model_name: gpt-4
litellm_params:
model: gpt-4
api_key: sk-1233
- model_name: claude-2
litellm_params:
model: claude-2
api_key: sk-claude
The proxy uses the first model in the config as the default model - in this config the default model is zephyr-alpha
Step 2: Start Proxy with config
$ litellm --config /path/to/config.yaml
Step 3: Use proxy
Curl Command
curl --location 'http://0.0.0.0:8000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "zephyr-alpha",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
Load Balancing - Multiple Instances of 1 model
Use this config to load balance between multiple instances of the same model. The proxy will handle routing requests (using LiteLLM's Router). Set rpm in the config if you want maximize throughput
Example config
requests with model=gpt-3.5-turbo will be routed across multiple instances of azure/gpt-3.5-turbo
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-eu
api_base: https://my-endpoint-europe-berri-992.openai.azure.com/
api_key:
rpm: 6 # Rate limit for this deployment: in requests per minute (rpm)
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key:
rpm: 6
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-large
api_base: https://openai-france-1234.openai.azure.com/
api_key:
rpm: 1440
Step 2: Start Proxy with config
$ litellm --config /path/to/config.yaml
Step 3: Use proxy
Curl Command
curl --location 'http://0.0.0.0:8000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
Fallbacks + Cooldowns + Retries + Timeouts
If a call fails after num_retries, fall back to another model group.
If the error is a context window exceeded error, fall back to a larger model group (if given).
Set via config
model_list:
- model_name: zephyr-beta
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8001
- model_name: zephyr-beta
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8002
- model_name: zephyr-beta
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8003
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
api_key: <my-openai-key>
- model_name: gpt-3.5-turbo-16k
litellm_params:
model: gpt-3.5-turbo-16k
api_key: <my-openai-key>
litellm_settings:
num_retries: 3 # retry call 3 times on each model_name (e.g. zephyr-beta)
request_timeout: 10 # raise Timeout error if call takes longer than 10s
fallbacks: [{"zephyr-beta": ["gpt-3.5-turbo"]}] # fallback to gpt-3.5-turbo if call fails num_retries
context_window_fallbacks: [{"zephyr-beta": ["gpt-3.5-turbo-16k"]}, {"gpt-3.5-turbo": ["gpt-3.5-turbo-16k"]}] # fallback to gpt-3.5-turbo-16k if context window error
allowed_fails: 3 # cooldown model if it fails > 1 call in a minute.
Set dynamically
curl --location 'http://0.0.0.0:8000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "zephyr-beta",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"fallbacks": [{"zephyr-beta": ["gpt-3.5-turbo"]}],
"context_window_fallbacks": [{"zephyr-beta": ["gpt-3.5-turbo"]}],
"num_retries": 2,
"request_timeout": 10
}
'
Config for Embedding Models - xorbitsai/inference
Here's how you can use multiple llms with one proxy config.yaml.
Here is how LiteLLM calls OpenAI Compatible Embedding models
Config
model_list:
- model_name: custom_embedding_model
litellm_params:
model: openai/custom_embedding # the `openai/` prefix tells litellm it's openai compatible
api_base: http://0.0.0.0:8000/
- model_name: custom_embedding_model
litellm_params:
model: openai/custom_embedding # the `openai/` prefix tells litellm it's openai compatible
api_base: http://0.0.0.0:8001/
Run the proxy using this config
$ litellm --config /path/to/config.yaml
Managing Auth - Virtual Keys
Grant other's temporary access to your proxy, with keys that expire after a set duration.
Requirements:
- Need to a postgres database (e.g. Supabase)
You can then generate temporary keys by hitting the /key/generate endpoint.
Step 1: Save postgres db url
model_list:
- model_name: gpt-4
litellm_params:
model: ollama/llama2
- model_name: gpt-3.5-turbo
litellm_params:
model: ollama/llama2
general_settings:
master_key: sk-1234 # [OPTIONAL] if set all calls to proxy will require either this key or a valid generated token
database_url: "postgresql://<user>:<password>@<host>:<port>/<dbname>"
Step 2: Start litellm
litellm --config /path/to/config.yaml
Step 3: Generate temporary keys
curl 'http://0.0.0.0:8000/key/generate' \
--h 'Authorization: Bearer sk-1234' \
--d '{"models": ["gpt-3.5-turbo", "gpt-4", "claude-2"], "duration": "20m"}'
models: list or null (optional) - Specify the models a token has access too. If null, then token has access to all models on server.duration: str or null (optional) Specify the length of time the token is valid for. If null, default is set to 1 hour. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
Expected response:
{
"key": "sk-kdEXbIqZRwEeEiHwdg7sFA", # Bearer token
"expires": "2023-11-19T01:38:25.838000+00:00" # datetime object
}
Managing Auth - Upgrade/Downgrade Models
If a user is expected to use a given model (i.e. gpt3-5), and you want to:
- try to upgrade the request (i.e. GPT4)
- or downgrade it (i.e. Mistral)
- OR rotate the API KEY (i.e. open AI)
- OR access the same model through different end points (i.e. openAI vs openrouter vs Azure)
Here's how you can do that:
Step 1: Create a model group in config.yaml (save model name, api keys, etc.)
model_list:
- model_name: my-free-tier
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8001
- model_name: my-free-tier
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8002
- model_name: my-free-tier
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_base: http://0.0.0.0:8003
- model_name: my-paid-tier
litellm_params:
model: gpt-4
api_key: my-api-key
Step 2: Generate a user key - enabling them access to specific models, custom model aliases, etc.
curl -X POST "https://0.0.0.0:8000/key/generate" \
-H "Authorization: Bearer sk-1234" \
-H "Content-Type: application/json" \
-d '{
"models": ["my-free-tier"],
"aliases": {"gpt-3.5-turbo": "my-free-tier"},
"duration": "30min"
}'
- How to upgrade / downgrade request? Change the alias mapping
- How are routing between diff keys/api bases done? litellm handles this by shuffling between different models in the model list with the same model_name. See Code
Managing Auth - Tracking Spend
You can get spend for a key by using the /key/info endpoint.
curl 'http://0.0.0.0:8000/key/info?key=<user-key>' \
-X GET \
-H 'Authorization: Bearer <your-master-key>'
This is automatically updated (in USD) when calls are made to /completions, /chat/completions, /embeddings using litellm's completion_cost() function. See Code.
Sample response
{
"key": "sk-tXL0wt5-lOOVK9sfY2UacA",
"info": {
"token": "sk-tXL0wt5-lOOVK9sfY2UacA",
"spend": 0.0001065,
"expires": "2023-11-24T23:19:11.131000Z",
"models": [
"gpt-3.5-turbo",
"gpt-4",
"claude-2"
],
"aliases": {
"mistral-7b": "gpt-3.5-turbo"
},
"config": {}
}
}
Save Model-specific params (API Base, API Keys, Temperature, Headers etc.)
You can use the config to save model-specific information like api_base, api_key, temperature, max_tokens, etc.
Step 1: Create a config.yaml file
model_list:
- model_name: gpt-4-team1
litellm_params: # params for litellm.completion() - https://docs.litellm.ai/docs/completion/input#input---request-body
model: azure/chatgpt-v-2
api_base: https://openai-gpt-4-test-v-1.openai.azure.com/
api_version: "2023-05-15"
azure_ad_token: eyJ0eXAiOiJ
- model_name: gpt-4-team2
litellm_params:
model: azure/gpt-4
api_key: sk-123
api_base: https://openai-gpt-4-test-v-2.openai.azure.com/
- model_name: mistral-7b
litellm_params:
model: ollama/mistral
api_base: your_ollama_api_base
headers: {
"HTTP-Referer": "litellm.ai",
"X-Title": "LiteLLM Server"
}
Step 2: Start server with config
$ litellm --config /path/to/config.yaml
Load API Keys from Vault
If you have secrets saved in Azure Vault, etc. and don't want to expose them in the config.yaml, here's how to load model-specific keys from the environment.
os.environ["AZURE_NORTH_AMERICA_API_KEY"] = "your-azure-api-key"
model_list:
- model_name: gpt-4-team1
litellm_params: # params for litellm.completion() - https://docs.litellm.ai/docs/completion/input#input---request-body
model: azure/chatgpt-v-2
api_base: https://openai-gpt-4-test-v-1.openai.azure.com/
api_version: "2023-05-15"
api_key: os.environ/AZURE_NORTH_AMERICA_API_KEY
s/o to @David Manouchehri for helping with this.
Config for setting Model Aliases
Set a model alias for your deployments.
In the config.yaml the model_name parameter is the user-facing name to use for your deployment.
In the config below requests with model=gpt-4 will route to ollama/llama2
model_list:
- model_name: text-davinci-003
litellm_params:
model: ollama/zephyr
- model_name: gpt-4
litellm_params:
model: ollama/llama2
- model_name: gpt-3.5-turbo
litellm_params:
model: ollama/llama2
Caching Responses
Caching can be enabled by adding the cache key in the config.yaml
Step 1: Add cache to the config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
set_verbose: True
cache: # init cache
type: redis # tell litellm to use redis caching
Step 2: Add Redis Credentials to .env
LiteLLM requires the following REDIS credentials in your env to enable caching
REDIS_HOST = "" # REDIS_HOST='redis-18841.c274.us-east-1-3.ec2.cloud.redislabs.com'
REDIS_PORT = "" # REDIS_PORT='18841'
REDIS_PASSWORD = "" # REDIS_PASSWORD='liteLlmIsAmazing'
Step 3: Run proxy with config
$ litellm --config /path/to/config.yaml
Using Caching
Send the same request twice:
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
Control caching per completion request
Caching can be switched on/off per /chat/completions request
- Caching on for completion - pass
caching=True:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": true
}' - Caching off for completion - pass
caching=False:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": false
}'
Set Custom Prompt Templates
LiteLLM by default checks if a model has a prompt template and applies it (e.g. if a huggingface model has a saved chat template in it's tokenizer_config.json). However, you can also set a custom prompt template on your proxy in the config.yaml:
Step 1: Save your prompt template in a config.yaml
# Model-specific parameters
model_list:
- model_name: mistral-7b # model alias
litellm_params: # actual params for litellm.completion()
model: "huggingface/mistralai/Mistral-7B-Instruct-v0.1"
api_base: "<your-api-base>"
api_key: "<your-api-key>" # [OPTIONAL] for hf inference endpoints
initial_prompt_value: "\n"
roles: {"system":{"pre_message":"<|im_start|>system\n", "post_message":"<|im_end|>"}, "assistant":{"pre_message":"<|im_start|>assistant\n","post_message":"<|im_end|>"}, "user":{"pre_message":"<|im_start|>user\n","post_message":"<|im_end|>"}}
final_prompt_value: "\n"
bos_token: "<s>"
eos_token: "</s>"
max_tokens: 4096
Step 2: Start server with config
$ litellm --config /path/to/config.yaml
Debugging Proxy
Run the proxy with --debug to easily view debug logs
litellm --model gpt-3.5-turbo --debug
When making requests you should see the POST request sent by LiteLLM to the LLM on the Terminal output
POST Request Sent from LiteLLM:
curl -X POST \
https://api.openai.com/v1/chat/completions \
-H 'content-type: application/json' -H 'Authorization: Bearer sk-qnWGUIW9****************************************' \
-d '{"model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "this is a test request, write a short poem"}]}'
Health Check LLMs on Proxy
Use this to health check all LLMs defined in your config.yaml
Request
curl --location 'http://0.0.0.0:8000/health'
You can also run litellm -health it makes a get request to http://0.0.0.0:8000/health for you
litellm --health
Response
{
"healthy_endpoints": [
{
"model": "azure/gpt-35-turbo",
"api_base": "https://my-endpoint-canada-berri992.openai.azure.com/"
},
{
"model": "azure/gpt-35-turbo",
"api_base": "https://my-endpoint-europe-berri-992.openai.azure.com/"
}
],
"unhealthy_endpoints": [
{
"model": "azure/gpt-35-turbo",
"api_base": "https://openai-france-1234.openai.azure.com/"
}
]
}
Logging Proxy Input/Output - Langfuse
We will use the --config to set litellm.success_callback = ["langfuse"] this will log all successfull LLM calls to langfuse
Step 1 Install langfuse
pip install langfuse
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Expected output on Langfuse
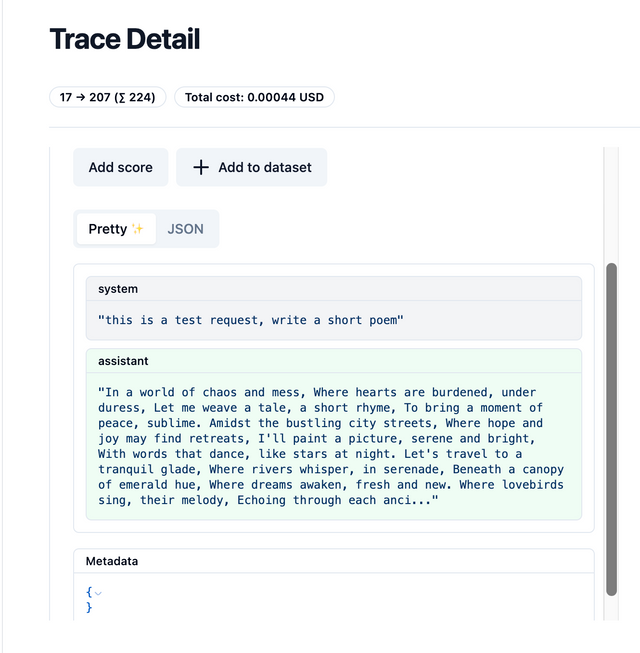
LiteLLM Proxy Performance
Throughput - 30% Increase
LiteLLM proxy + Load Balancer gives 30% increase in throughput compared to Raw OpenAI API
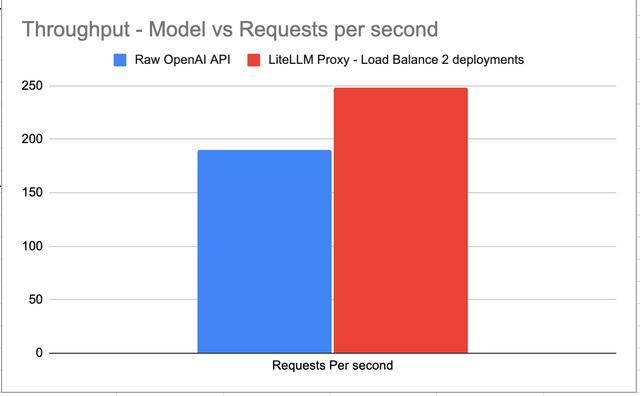
Latency Added - 0.00325 seconds
LiteLLM proxy adds 0.00325 seconds latency as compared to using the Raw OpenAI API
Proxy CLI Arguments
--host
- Default:
'0.0.0.0' - The host for the server to listen on.
- Usage:
litellm --host 127.0.0.1
--port
- Default:
8000 - The port to bind the server to.
- Usage:
litellm --port 8080
--num_workers
- Default:
1 - The number of uvicorn workers to spin up.
- Usage:
litellm --num_workers 4
--api_base
- Default:
None - The API base for the model litellm should call.
- Usage:
litellm --model huggingface/tinyllama --api_base https://k58ory32yinf1ly0.us-east-1.aws.endpoints.huggingface.cloud
--api_version
- Default:
None - For Azure services, specify the API version.
- Usage:
litellm --model azure/gpt-deployment --api_version 2023-08-01 --api_base https://<your api base>"
--model or -m
- Default:
None - The model name to pass to Litellm.
- Usage:
litellm --model gpt-3.5-turbo
--test
- Type:
bool(Flag) - Proxy chat completions URL to make a test request.
- Usage:
litellm --test
--health
- Type:
bool(Flag) - Runs a health check on all models in config.yaml
- Usage:
litellm --health
--alias
- Default:
None - An alias for the model, for user-friendly reference.
- Usage:
litellm --alias my-gpt-model
--debug
- Default:
False - Type:
bool(Flag) - Enable debugging mode for the input.
- Usage:
litellm --debug
--temperature
- Default:
None - Type:
float - Set the temperature for the model.
- Usage:
litellm --temperature 0.7
--max_tokens
- Default:
None - Type:
int - Set the maximum number of tokens for the model output.
- Usage:
litellm --max_tokens 50
--request_timeout
- Default:
600 - Type:
int - Set the timeout in seconds for completion calls.
- Usage:
litellm --request_timeout 300
--drop_params
- Type:
bool(Flag) - Drop any unmapped params.
- Usage:
litellm --drop_params
--add_function_to_prompt
- Type:
bool(Flag) - If a function passed but unsupported, pass it as a part of the prompt.
- Usage:
litellm --add_function_to_prompt
--config
- Configure Litellm by providing a configuration file path.
- Usage:
litellm --config path/to/config.yaml
--telemetry
- Default:
True - Type:
bool - Help track usage of this feature.
- Usage:
litellm --telemetry False